
油价上演极限反转,长下影线稳住局势,市场信心仍处于低位
要与市场保持一段距离而它的瞬息万变不过是人性瞬息万变的一个汇聚。选择这个市场,本质是选择直视错踪复杂的人性,走火入魔式的...
2024-06-06
粉丝1:怎么到处自媒体甚至所谓的大V都贴出说恒大欠小招113亿?
我:这问题我说了很多次了,不想重复回答。自己去翻历史贴
粉丝2:谷老师 求教 全网传招行有恒大借款113亿 这是啥情况呢?
我:自己去翻历史文章,全网都是SB
粉丝3:SMN的播客里谈恒大问题的时候列出了招行给恒大贷款113亿,排名第三。
我:SMN这种到处蹭流量的水货能有什么专业见解?
隔着屏幕都能闻到那满满的焦虑感:大家都这么说,大家都错了么?万一大家说对了,怎么办?我相信,如果这时候再来个大跌,那么90%的人都会更加确信这是真的。
其实这个事情早在2年前我就说过了,纯属子虚乌有。而且,针对这个问题早在2年前官方就给出了正式的答复,参考如下图1:
图1
图1是我从上交所官网,互动e栏目截取的问答截图。投资者_395680通过互动e向招行董秘提问:招行对恒大集团的贷款有多少?上半年计提多少坏账?招行董秘的官方回答是:“截至2021年6月30日,我行表内资产及理财产品底层资产中无涉及恒大的风险敞口,不需要计提损失准备。”
这个声明我在公开发布的文章中也曾引用过。这种陈年冷饭还能被拿出来爆炒,主要是和许皮带被捕有关。现在很多自媒体,up主都是蹭流量博眼球,完全没有任何专业认知,这其中不乏某些靠流量活着的网红,大V。反正这些人蹭流量就跟放屁排泄一样每天不能停,就算说错了过两天大家也就忘了。
其实,关于恒大欠各家金融机构多少钱,最先也是从网上流传出来的。我还曾经看过某些网络表格的截图,如下图2所示:
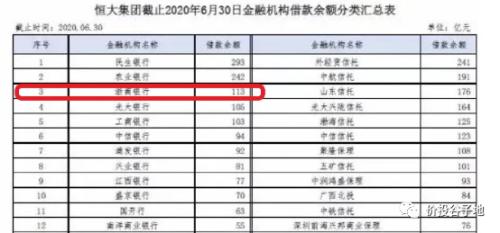
图2
从图2中我们可以看到,表头是“恒大集团截止2020年6月30日金融机构借款余额分类汇总表”。其中画红圈的确实是113亿,也确实是第三名。但是,金融机构的名称并不是招商银行,而是浙商银行。如果把图1作为证据1,那么图2作为证据2,这两个证据都证明了招行并没有向恒大贷款113亿。除此之外,我们还可以从恒大历年年报披露的主要合作银行列表中去寻找佐证。下图3是某位网友给我提供的历年恒大合作银行列表:
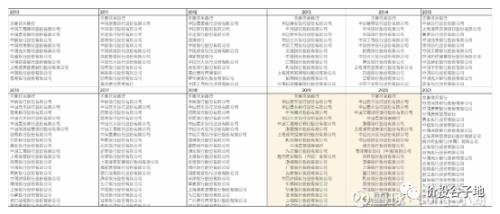
图3
首先需要说明的是,我没有去复核图3信息的准确性,毕竟有了图1的证据,我懒得去花时间证明一件不存在的事情。我们假设图3的信息是准确的。从图3我们可以看到招商银行在2011,2013,2014,2016,2017,2018这六年里都是恒大集团的主要合作银行。其中,2017,2018两年更是排在第三名。但是,从2019年之后招商银行再没有出现在恒大的主要合作银行列表中。这信息如果是真的,就从侧面印证了图1中招行董秘的回答。
那么对于图2中浙商银行在2020年6月30日给恒大贷款113亿排名第三的信息可信么?个人认为基本可信,因为在今年浙商银行的中报业绩发布会上,浙商银行的高管对此进行了相关披露:
浙商银行行长助理 (拟任)潘华枫表示,我们在房地产行业风险管控中采取了一些措施,在房地产行业风险暴露初期快速压降了部分风险。潘华枫举例表示,比如恒大在我行的授信最高的峰值曾经达到过200多亿,目前我们行对恒大集团的整个授信敞口只有20多个亿,而且基本在抵押项下。
从潘行助(拟任)的披露中我们可以看到曾经浙商银行对恒大的授信最高达到200多亿。那么图2表中的113亿就比较合理了。
根据目前的证据,虽然我还不能确定。但是,我猜测关于招行给恒大贷款113亿的谣言可能有两种情况:
可能1:误传
当初,图2还未公开披露时,有些人先看到了这份表格。然后,在向外散播消息的时候为了回避泄密被追究的可能就用了银行拼音首字母缩写,比如:1,MSYH 293亿,2,NYYH 242亿,3,ZSYH 113亿。对于缩写大部分银行时可以被无歧义猜出来的。但是,到了ZSYH这里歧义就产生了,ZSYH既可以是招商银行的拼音首字母缩写,也可以是浙商银行的。
由于浙商银行成立时间不长,规模较小。很多读者可能根本没听说过浙商银行,所以按照惯性思维就把这笔贷款安在了招商银行头上。然后,以讹传讹,一传十,十传百。
可能2:恶意造谣
第二种情况就比较恶劣了。不排除有人恶意篡改相应的信息,借着许皮带被捕的事件热度,蹭热度散播虚假信息。妄图在招行严重低估的大背景下制造恐慌从中渔利。
文章的最后,我再来顺手吐槽一下前一段事件比较火的ChatGPT。关于招行给恒大贷款113亿的谣言。我特意找了国内某免费ChatGPT平台试了一下,看看ChatGPT会怎么产生答复。我先提了一个简单的问题,如下图4所示:

图4
图4系统给出的答复基本上代表了目前网络答案的统计情况,即谣言为主。于是,我追加了第二个问题,如下图5所示:

图5
图5中系统虽然修正了回答并且增加了免责用的话术,但是它给出的答案仍旧是招行给恒大贷款113亿,并且说此信息来源于招行的年报和相关公告。由此可见,网络中关于此谣言的脏数据不仅数据量大,而且还进行了伪装,拿出年报和公告唬人。我继续追加紧逼问题,如下图6所示:
图6
图6显示,系统怂了承认年报里没有这一信息,但是坚称之前的回答数据可能来源于其他公开信息或者媒体报道。
从上面的测试可以看出,ChatGPT不过是一个带有自然语言处理外壳的搜索引擎。它并不能判断答案的正确性,只能依靠搜索结果的统计信息给出重复最多的答案。但是,在目前网络谣言漫天飞的环境中,没有经过专家系统校验的垃圾数据喂给ChatGPT的结果就是:垃圾进,垃圾出。
其实,ChatGPT的现状正是现有人群使用互联网获取信息的缩影。很多时候真理并不掌握在多数人手中,而且多数SB的共识也是共识。
要与市场保持一段距离而它的瞬息万变不过是人性瞬息万变的一个汇聚。选择这个市场,本质是选择直视错踪复杂的人性,走火入魔式的...


汇通网5月13日讯―― 作为一种投资,黄金在未来十年很可能会落后于美国通胀超过7%。 马克・哈尔伯特(Mark Hulb...
原标题:国富恒利债券(LOF)C : 富兰克林国海恒利债券型证券投资基金(LOF)暂停大额申购、定期定额投资的公告...
当前非电脑浏览器正常宽度,请使用移动设备访问本站!